What is Power Analysis? : Power Analysis
What is Power Analysis?
Traditionally, data collected in a research study is submitted to a significance test to assess the viability of the null hypothesis. The p-value provided by the significance test, and used to reject the null hypothesis, is a function of three factors: The larger the observed effect, the larger the sample size, and/or the more liberal the criterion required for significance (alpha), the more likely it is that the test will yield a significant p-value.
A power analysis, executed when the study is being planned, is used to anticipate the likelihood that the study will yield a significant effect and is based on the same factors as the significance test itself. Specifically, the larger the effect size used in the power analysis, the larger the sample size, and/or the more liberal the criterion required for significance (alpha), the higher the expectation that the study will yield a statistically significant effect.
These three factors, together with power, form a closed system - once any three are established, the fourth is completely determined. The goal of a power analysis is to find an appropriate balance among these factors by taking into account the substantive goals of the study, and the resources available to the researcher.
Role of Effect Size in Power Analysis
The term "effect size" refers to the magnitude of the effect under the alternate hypothesis. The nature of the effect size will vary from one statistical procedure to the next (it could be the difference in cure rates, or a standardized mean difference, or a correlation coefficient) but its function in power analysis is the same in all procedures.
The effect size should represent the smallest effect that would be of clinical or substantive significance, and for this reason it will vary from one study to the next. In clinical trials for example, the selection of an effect size might take account of the severity of the illness being treated (a treatment effect that reduces mortality by one percent might be clinically important while a treatment effect that reduces transient asthma by 20% may be of little interest). It might take account of the existence of alternate treatments (if alternate treatments exist, a new treatment would need to surpass these other treatments to be important). It might also take account of the treatment's cost and side effects (a treatment that carried these burdens would be adopted only if the treatment effect was very substantial).
Power analysis gives power for a specific effect size. For example, the researcher might report "If the treatment increases the recovery rate by 20 percentage points the study will have power of 80% to yield a significant effect". For the same sample size and alpha, if the treatment effect is less than 20 points then power will be less than 80%. If the true effect size exceeds 20 points, then power will exceed 80%.
While one might be tempted to set the "clinically significant effect" at a small value to ensure high power for even a small effect, this determination cannot be made in isolation. The selection of an effect size reflects the need for balance between the size of the effect that we can detect, and the resources available for the study.
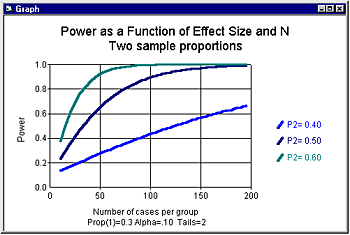
Small effects will require a larger investment of resources than large effects. Figure 1 shows power as a function of sample size for three levels of effect size (assuming alpha, 2-tailed, is set at .05). For the smallest effect (30% vs. 40%) we would need a sample of 356 per group to yield power of 80%. For the intermediate effect (30% vs. 50%) we would need a sample of 93 per group to yield this level of power. For the highest effect size (30% vs. 60%) we would need a sample of 42 per group to yield power of 80%. We may decide that it would make sense to enroll 93 per group to detect the intermediate effect but inappropriate to enroll 356 patients per group to detect the smallest effect.
The "true" (population) effect size is not known. While the effect size in the power analysis is assumed to reflect the population effect size for the purpose of calculations, the power analysis is more appropriately expressed as "If the true effect is this large power would be ..." rather than "The true effect is this large, and therefore power is ...".
This distinction is an important one. Researchers sometimes assume that a power analysis cannot be performed in the absence of pilot data. In fact, it is usually possible to perform a power analysis based entirely on a logical assessment of what constitutes a clinically (or theoretically) important effect. Indeed, while the effect observed in prior studies might help to provide an estimate of the true effect it is not likely to be the true effect in the population - if we knew that the effect size in these studies was accurate, there would be no need to run the new study.
Since the effect size used in power analysis is not the "true" population value, the researcher may elect to present a range of power estimates. For example (assuming N=93 per group and alpha=.05, 2 tailed), "The study will have power of 80% to detect a treatment effect of 20 points (30% vs. 50%), and power of 99% to detect a treatment effect of 30 points (30% vs. 50%)".
Cohen has suggested "conventional" values for "small", "medium" and "large" effects in the social sciences. The researcher may want to use these values as a kind of reality-check, to ensure that the values he/she has specified make sense relative to these anchors. The program also allows the user to work directly with one of the conventional values rather than specifying an effect size, but it is preferable to specify an effect based on the criteria outlined above, rather than relying on conventions.
Power Analysis - Role of Alpha
The significance test yields a p-value that gives the likelihood of the study effect, given that the null hypothesis is true. For example, a p-value of .02 means that, assuming that the treatment has no effect, and given the sample size, an effect as large as the observed effect would be seen in only 2% of studies.
The p-value obtained in the study is evaluated against the criterion, alpha. If alpha is set at .05, then a p-value of .05 or less is required to reject the null hypothesis and establish statistical significance.
If a treatment really is effective and the study succeeds in rejecting the null, or if a treatment really has no effect and the study fails to reject the null, the study's result is correct. A Type I error is said to occur if the treatment really has no effect but we mistakenly reject the null. A Type II error is said to occur if the treatment is effective but we fail to reject the null.
Assuming the null is true and alpha is set at .05 we would expect a type I error to occur in 5% of all studies - the Type I error rate is equal to alpha. Assuming the null is false (and the true effect is given by the effect size used in computing power) we would expect a type II error to occur in the proportion of studies denoted by one minus power, and this error rate is known as beta.
Power Analysis - Role of Tails
The significance test is always defined as either one-tailed or two-tailed. A two-tailed test is a test that will be interpreted if the effect meets the criterion for significance and falls in either direction, and is appropriate for the vast majority of research studies. A one-tailed test is a test that will be interpreted only if the effect meets the criterion for significance and falls in the observed direction (i.e. the treatment improves the cure rate), and is appropriate only for a specific type of research question.
Cohen gives the following example of a one-tailed test. An assembly line is currently using a particular process (A). We are planning to evaluate an alternate process (B) which would be expensive to implement but could yield substantial savings if it works as expected. The test has three possible outcomes: (1) Process A is better; (2) There is no difference between the two; (3) Process (B) is better. However, for our purposes, outcomes (1) and (2) are functionally equivalent since either would lead us to maintain the status quo. Put another way, we have no need to distinguish between outcomes (1) and (2).
A one-tailed test should be used only in a study in which, as in this example, an effect in the unexpected direction is functionally equivalent to no effect. It is not appropriate to use a one-tailed test simply because one is able to specify the expected direction of the effect prior to running the study. In medicine, for example, we typically expect that the new procedure will improve the cure rate, but a finding that it decreases the cure rate would still be important, since it would demonstrate a possible flaw in the underlying theory.
For a given effect size, sample size, and alpha, a one-tailed test is more powerful than a two-tailed test (a one-tailed test with alpha set at .05 has approximately the same power as a two-tailed test with alpha set at .10). However, the number of tails should be set based on the substantive issue (will an effect in the reverse direction be meaningful). In general, it would not be appropriate to run a test as one-tailed rather than two-tailed as a means of increasing power. (Power is higher for the one-tailed test only under the assumption that the observed effect falls in the expected direction. When the test is one tailed, power for an effect in the reverse direction is nil).
Role of Sample Size in Power Analysis
For any given effect size and alpha, increasing the sample size will increase the power (ignoring for the moment the case of power for a single proportion by the binomial method). As is true of effect size and alpha, sample size cannot be viewed in isolation but rather as one element in a complex balancing act. In some studies it might be important to detect even a small effect while maintaining high power. In this case it might be appropriate to enroll many thousands of patients (as was done in the "Physicians" study that found a relationship between aspirin use and cardiovascular events).
Typically, though, the number of available cases is limited. The researcher might need to find the largest N that can be enrolled, and work backwards from there to find an appropriate balance between alpha and beta. She may need to forgo the possibility of finding a small effect, and acknowledge that power will be adequate for a large effect only.
Note: For studies that involve two groups power is generally maximized when the subjects are divided evenly between the two groups. When the number of cases in the two groups is uneven the "effective N" for computing power falls much closer to the smaller sample size than the larger one.
Controlling Power
Power is the fourth element in this closed system - Given an effect size, and alpha, and sample size, power is known. As noted above, a "convention" exists that power should be set at 80% but this convention has no logical basis. The appropriate level of power should be decided on a case-by-case basis, taking into account the potential harm attendant on a Type I error, the determination of a clinically important effect, the potential sample size, as well as the importance of identifying an effect, should one exist.
Ethical Issues
Some studies involve putting patients at risk. At one extreme, the risk might involve a loss of time spent completing a questionnaire. At the other extreme, the risk might involve the use of an ineffective treatment for a potentially fatal disease. These issues are clearly beyond the scope of this discussion, but one point should be made here.
Ethical issues play a role in power analysis. If a study to test a new drug will have adequate power with a sample of 100 patients, then it would be inappropriate to use a sample of 200 patients since the second 100 are being put at risk unnecessarily. At the same time, if the study requires 200 patients to yield adequate power, it would be inappropriate to use only 100. These 100 patients may consent to take part in the study on the assumption that the study will yield useful results. If the study is under-powered, then the 100 patients have been put at risk for no reason.
Of course, the actual decision making process is complex. One can argue about whether "adequate" power for the study is 80%, or 90%, or 99%. One can argue about whether power should be set based on an improvement of 10 points, or 20 points, or 30 points. One can argue about the appropriate balance between alpha and beta. The point being made here is that these kinds of issues need to be addressed explicitly as part of the decision making process.
Null Hypothesis vs. Nil Hypothesis
Power analysis focuses on the study's potential for rejecting the null hypothesis. In most cases the null hypothesis is the null hypothesis of no effect (a.k.a. the nil hypothesis). For example, the researcher is testing a null hypothesis that the change score from time-1 to time-2 is zero. In some studies, however, the researcher might attempt to disprove the null hypothesis other than the nil. For example, "The intervention boosts the scores by 20 points or more". The impact of this is to change the effect size.

"This software is great and the ease of use is amazing. I normally use [another program] and was prepared to spend hours...With your program I had the graphs in minutes and the graphs got it exactly right. An incredible effort. Thanks!!"
Ricardo Pietrobon - Director of Outcomes Research, Division of Orthopedic Surgery and Ambulatory Anesthesia, Duke University
Power and Precision

Power and Precision is a statistical power analysis software package for calculation of a sample size for a planned study. The program features an unusually clear interface, and many tools to assist the user in developing an understanding of power analysis.